Longitudinal Data Linking in SESTAT
Some respondents in the National Survey of College Graduates (NSCG), Survey of Doctorate Recipients (SDR), and National Survey of Recent College Graduates (NSRCG) are surveyed multiple times, providing opportunities for longitudinal data analysis. The variable PERSONID identifies individuals across survey years. (It replaces the original variable, REFID, which contains non-numeric values in some samples.) Users should note that in a small number of cases, gender and other time-invariant characteristics conflict when two individuals are matched between samples.
Another potentially useful variable, COHORT, identifies the original survey through which the respondent first entered the SESTAT database.
IPUMS Higher Ed does not provide linked longitudinal files; however, users can download the samples they desire and easily link them using a statistical program, merging by PERSONID. At the bottom of this page, we provide an example of Stata commands to merge SESTAT datasets.
Below is an adapted graphic from the NSF describing the longitudinal patterns of respondents to the NSCG, NSRCG, and the SDR. New cohorts of the NSCG comes from the decennial Census (for 1990 and 2000) or the ACS (for 2010), and new cohorts of the SDR are selected from the Doctorate Records File.
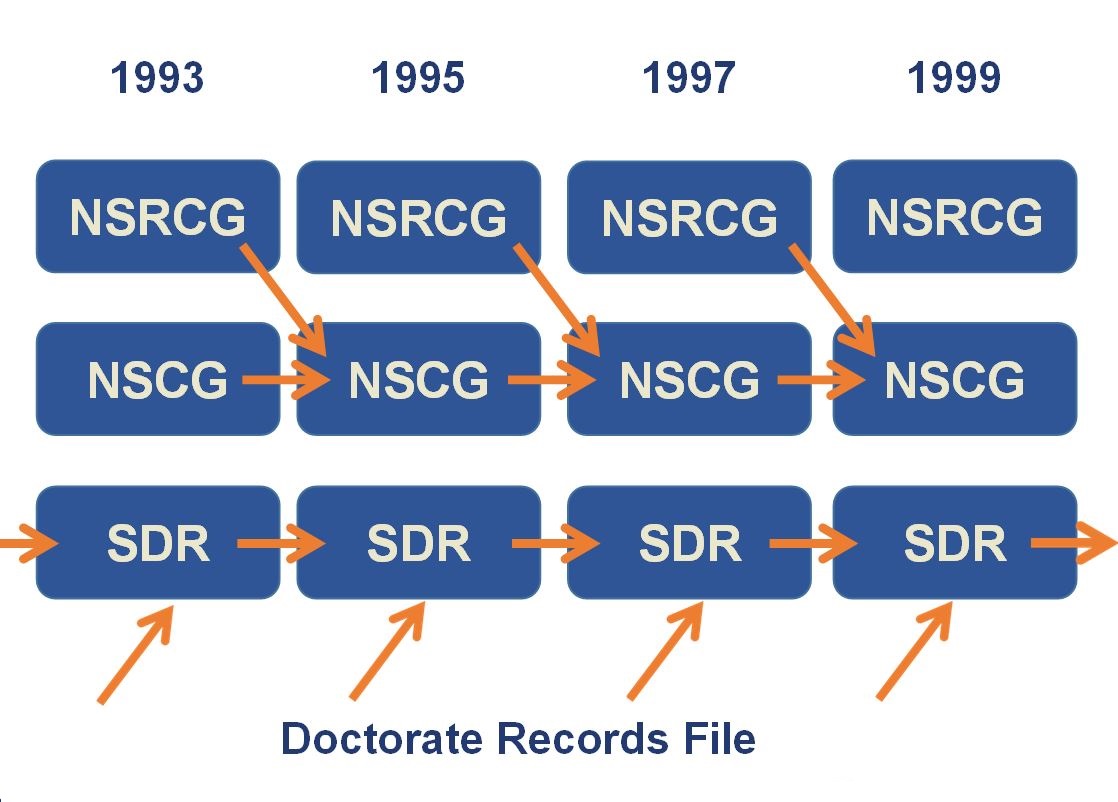
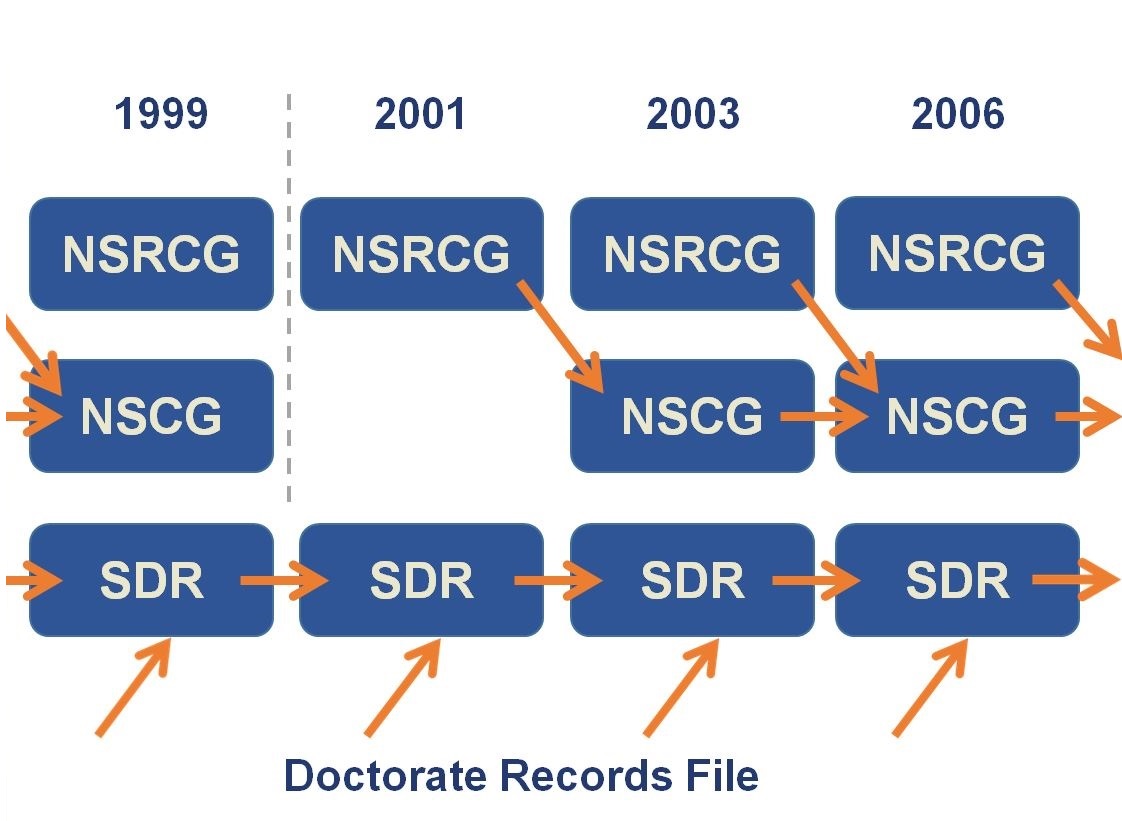
Source: National Science Foundation
National Survey of College Graduates
For the 1993 and 2003 surveys, individuals for the NSCG were selected by using the education responses of the Decennial Census long-form questionnaire to identify college graduates. These respondents received the NSCG survey every two to three years until a new sample group was selected, that is, until the end of the decade. Starting in 2010, the NSCG respondents are chosen using education responses in the American Community Survey.
Survey of Doctorate Recipients
Once a respondent is selected for the Survey of Doctorate Recipients, the NSF sends them a follow-up survey every 2 to 3 years until they reach the age of 76. New individuals are chosen for each iteration of the survey as individuals inevitably drop out due to age or non-response. The result is that the sizes of the SDR files are relatively stable over time. Unlike the NSRCG and NSCG, there are no discontinuations in cohorts associated with the Decennial Census.
National Survey of Recent College Graduates
A new group of participants were selected for each round of the NSRCG, because the target population was non-institutionalized individuals under the age of 76 who had earned a bachelor's or master's degree in the past two years. After the initial NSRCG survey, respondents are folded into the next iteration of the NSCG survey until the end of the decade.
Stata version
The values in the foreach loop represent sample values. In this example, we link individuals across the NSRCG 1993, NSCG 1995, and NSCG 1997. Look up the codes on the SAMPLE codes tab, and replace "103 201 301" with your sample codes, delimited by a space. Also, change the ### so that the line replicates the name of the extract you downloaded from the IPUMS-Higher Ed extract system.
foreach value of numlist 103 201 301 {
do highered_00###
//reads in the Stata do-file you downloaded with your data file
keep if sample==`value'
foreach var of varlist rectype-lastvar {
rename `var' `var'_`value' //renames all variables with the
//sample name to distinguish later,
//and to prevent the values being overwritten
}
cap save sample_`value', replace
clear
}
use sample_103
foreach value of numlist 201 301 {
merge 1:1 personid using "sample_`value'.dta", gen(_merge`value')
//merges the cases of the same respondent from
//different years onto the same row, one sample at a time
}
In regards to the varlist syntax above, 'varlist' must followed by the varname of the first and last variables in your list. 'rectype' will be the first variable name in most extracts and the user must input the variable name of the last variable in their list in the place of 'lastvar.'
Supported By
![]()
![]()
![]()